

Large language models (LLMs) have significantly changed the landscape of natural language processing, allowing machines to understand and generate human language much more effectively than ever before. Typically, these models are pre-trained on huge and parallel corpora and then fine-tuned to connect them to human tasks or preferences. Therefore, this process has led to great advancements in the field, making the LLMs very useful tools for various applications, from language translation to sentiment analysis. Active research continues to be conducted on the relationship between pre-training and fine-tuning, as this understanding will lead to further optimization of the models for better performance and utility.
One of the challenges in training the LLMs is the trade-off between the benefits of the pre-training phase and the fine-tuning phase. Pre-training was key to equipping models with broad language understanding, but it is often questionable how optimal this pre-training point is before fine-tuning. While this is sometimes necessary to condition the model to a specific task, it can sometimes lead to loss of previously learned information or embedding biases that were not initially present during the model’s pre-training. It is a delicate balance between preserving general knowledge and fine-tuning to perform specific tasks.
Existing approaches perform pretraining and fine-tuning in two separate steps: Pretraining involves presenting the model with a huge text dataset containing a huge vocabulary, which the model uses to learn to recognize the underlying structures and patterns of language. Fine-tuning involves continuing training on smaller, task-specific datasets to specialize the model for specific tasks. A general pretraining followed by a task-specific fine-tuning approach can likely only fulfill some of the potential synergies in the two phases. Researchers have begun to investigate whether a more integrated approach, introducing fine-tuning at multiple intersection points in the pretraining process, would achieve better performance.
A new method from a research group at Johns Hopkins University examined the trade-off between pretraining and fine-tuning. The authors also investigated how continuous pretraining affects the capabilities of fine-tuned models by fine-tuning many intermediate checkpoints of a pre-trained model. The experiments were conducted on large-scale big data models that were pre-trained and used checkpoints from different stages of the pretraining process. Fine-tuning of checkpoints at different points in model development was done using a supervised and instruction-based approach. This new method helped the researchers compare how their model performs compared to others at different stages of the development process, revealing the best strategies for training LLMs.
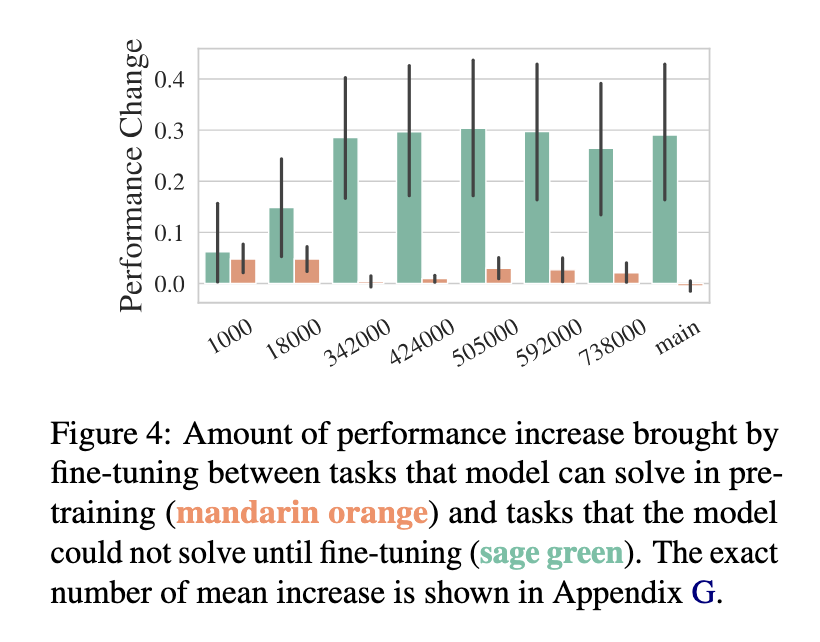
The methodology is in-depth and discusses the model’s performance on several tasks such as natural language recognition, paraphrase detection, and summarization on 18 datasets. They concluded that continuous pre-training leads to potential hidden opportunities in the model that are only revealed after fine-tuning. In particular, tasks where the model initially underperformed during pre-training showed significant improvements after fine-tuning, with overall improvement for the tasks ranging from 10% to 30%. In contrast, features where the model performed satisfactorily in the pre-training phase showed less dramatic improvements in the fine-tuning phase, implying that fine-tuning benefits tasks for which it was not sufficiently learned beforehand.
The study also uncovered certain subtle features related to the fine-tuning process. While fine-tuning generally improves the model’s performance, on the other hand, it causes the model to forget the information it has already learned, as this mostly happens when the fine-tuning objective does not match the pre-training objective, which are tasks that are not directly related to the goals of fine-tuning. For example, after fine-tuning several natural language inference tasks, the model deteriorates when evaluated on a paraphrase identification task. These behaviors have shown a trade-off between improvement on the fine-tuned task and more general abilities. Experimentally, they show that this type of forgetting can be partially mitigated by continuing the massive pre-training steps during the fine-tuning phases, thus preserving the knowledge base of the large model.

The performance results of the fine-tuned models were interesting. On the natural language recognition tasks, the fine-tuned model showed a peak performance of 25% compared to the pre-trained model. The accuracy on the paraphrase recognition task improved by 15%, while it improved by about 20% on both summarization tasks. These results strongly emphasize the importance of fine-tuning to truly exploit the full potential of pre-trained models, especially in cases where the base model performs poorly.
In summary, this work by researchers at Johns Hopkins University is very interesting as it provides insight into the dynamic relationship between pretraining and fine-tuning in additional LLMs. It is important to move on after laying a solid foundation in a preliminary phase; without it, the model fine-tuning process will not improve the model’s performance. The research shows that there is a proper balance between these two phases in performance, promising further new directions for NLP. This new direction will potentially lead to the effectiveness of training paradigms that apply pretraining and fine-tuning simultaneously, in a way that benefits more powerful and flexible language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Þjórsárden and join our Telegram channel And LinkedInphew. If you like our work, you will Newsletters..
Don’t forget to join our 48k+ ML SubReddit
Find upcoming AI webinars here
Nikhil is an intern at Marktechpost. He is pursuing an integrated double degree in Materials Science from the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is constantly researching applications in areas like biomaterials and biomedicine. With his strong background in materials science, he explores new advancements and creates opportunities to contribute.




